安装MySql 5.7 教程
1、下载MySQL安装包:
wget http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.17.tar.gz
2、安装依赖包:
MacOX: brew install cmake
brew install boost
brew install homebrew/dupes/ncurses
LINUX: yum -y install cmake
yum -y install bison
yum -y install ncurses-devel


3、解压mysql安装包 并编译安装
#创建mysql用户以及相关目录
groupadd mysql #所以在这里我们要建一个msyql的用户和组
groupadd mysql #所以在这里我们要建一个msyql的用户和组
useradd -g mysql mysql -s /usr/sbin/nologin
mkdir /usr/local/mysql5.7 #创建目录
mkdir /usr/local/mysql5.7/data
$ tar -zxf mysql-5.7.17.tar.gz
$ cd mysql-5.7.17
$ cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql5.7 -DDOWNLOAD_BOOST=1 -DWITH_BOOST=/usr/local/Cellar/boost/1.62.0 -DMYSQL_UNIX_ADDR=//usr/local/mysql5.7/data/mysql.sock -DMYSQL_USER=mysql -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_DEBUG=0 -DWITH_READLINE=1
#编译完成后开始安装
sudo make && make install
4、安装成功后 配置MySQL
#复制默认配置文件到 MySQL安装根目录下
sudo cp support-files/my-default.cnf /usr/local/mysql5.7/my.cnf
sudo vim /usr/local/mysql5.7/my.cnf
#配置文件内容
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
# *** DO NOT EDIT THIS FILE. It's a template which will be copied to the
# *** default location during install, and will be replaced if you
# *** upgrade to a newer version of MySQL.
[mysqld]
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
# These are commonly set, remove the # and set as required.
basedir =/usr/local/mysql5.7/
datadir =/usr/local/mysql5.7/data
log-error =/usr/local/mysql5.7/log/mysql.err
pid-file =/usr/local/mysql5.7/mysql.pid
port =3309
#server_id = .....
socket =/usr/local/mysql5.7/data/mysql.sock
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
join_buffer_size = 128M
sort_buffer_size = 2M
read_rnd_buffer_size = 2M
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
#skip-grant-tables
#保存配置文件后 初始化数据库
bin/mysqld --initialize --basedir=/usr/local/mysql5.7/ --datadir=/usr/local/mysql5.7/data --user=_mysql
5、启动MySQL服务
sudo support-files/mysql.server start
如果启动报错 请修改 /usr/local/mysql5.7 根目录 /usr/local/mysql5.7/log 和 /usr/local/mysql5.7/data 文件夹权限 和 拥有者为 _mysql
6、修改默认密码
sudo vim my.cnf # 将其中的 skip-grant-tables 选项前 # 好去掉 保存并退出
sudo support-files/mysql.server restart 重启MySQL服务
#进入MySQL
bin/mysql -uroot -p -P3309 -S/usr/local/mysql5.7/data/mysql.sock
#修改默认密码 并新建用户
UPDATE user SET authentication_string = password('123456') WHERE User = 'root';
flush privileges;
#新建用户
SET PASSWORD = PASSWORD('123456'); # root 用户密码
CREATE USER 'jiazhizhong'@'%' IDENTIFIED BY 'jia980709';
GRANT ALL ON *.* TO 'jiazhizhong'@'%';
flush privileges;
exit;
#重新启动MySQL服务
sudo support-files/mysql.server restart
7、MySQL安装中遇到的错误 及 解决办法
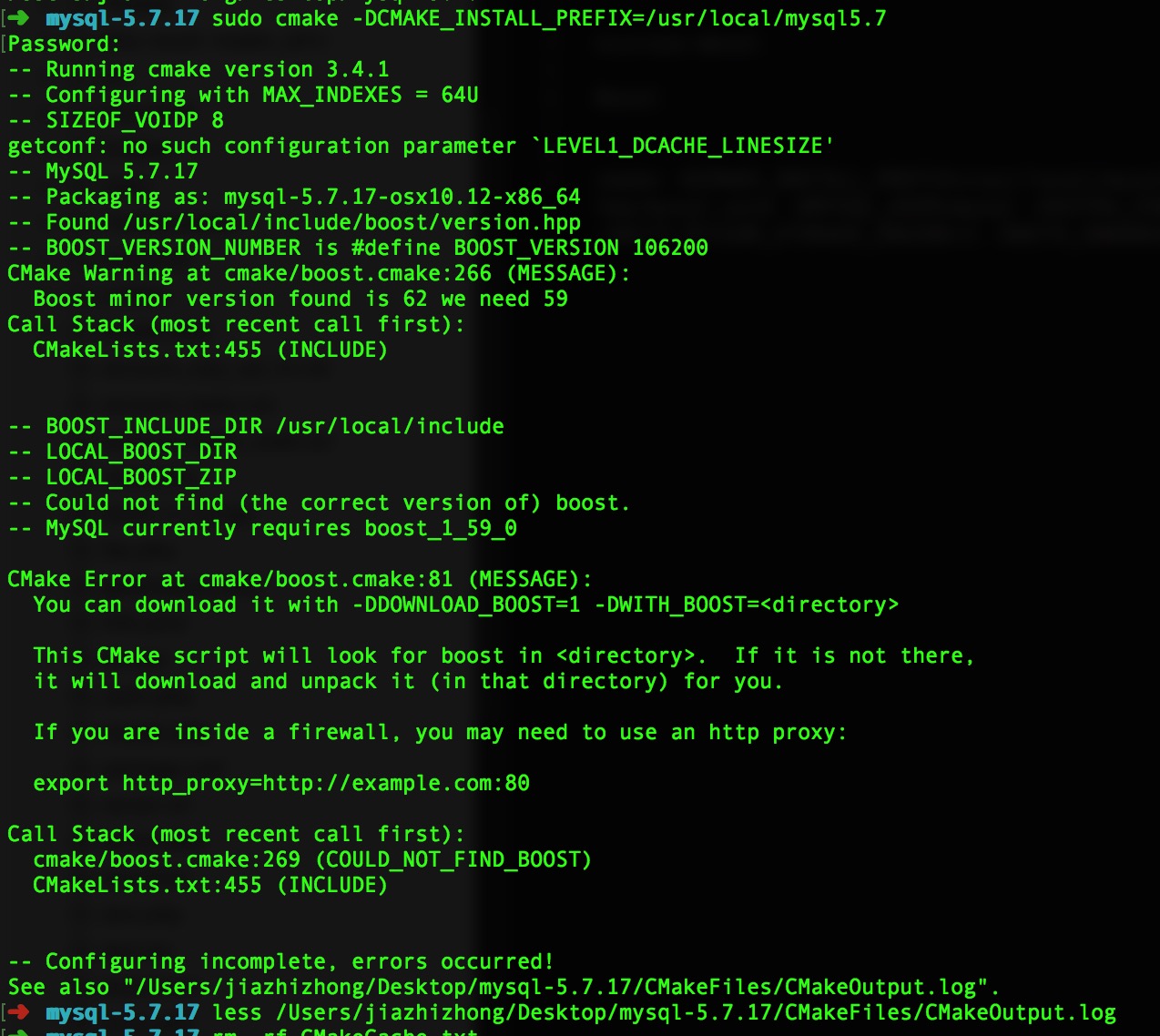
7.1、遇到这个错误 是你没安装 boost 或没指定 boost 路径 (-DDOWNLOAD_BOOST=1 -DWITH_BOOST=/usr/local/Cellar/boost/1.62.0)
7.2、遇到下面这个错误是在 执行 mysql -uroot -p123456 命令或者是重启MySQL服务时遇到,将 my.cnf 文件中 socket 地址配置正确即可
**Can’t connect to local MySQL server through socket ‘/tmp/mysql.sock**
7.3、这个错误是在命令行下登录进入MySQL后执行sql语句时报错,这个错误需要你执行 (SET PASSWORD = PASSWORD('123456'); # root 用户密码)这条sql 设定下root密码即可
**ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.**
8、查看MySQL配置文件路径
#如果是linux系统,使用:
#第一种
sudo find / -name my.cnf
#第二种
sudo mysql --help | grep my.cnf